Digital Humanities 2018: Post-Conference Debriefing
For the second year in a row, the ISAW Library was represented at the annual conference for Alliance of Digital Humanities Organizations—DH2018, as the meeting is called—held this year from June 26-29 in Mexico City. I presented a paper on my research on building the next generation of text analysis tools for historical languages with the Classical Language Toolkit, entitled “Backoff Lemmatization as a Philological Method.” More on this below. Suffice it to say that the paper was well received: it spurred an interesting discussion about not just the future of text analysis tools for Latin (which was the main focus of the paper) but also how this research will benefit the development of language resources for a wide range of historical languages.
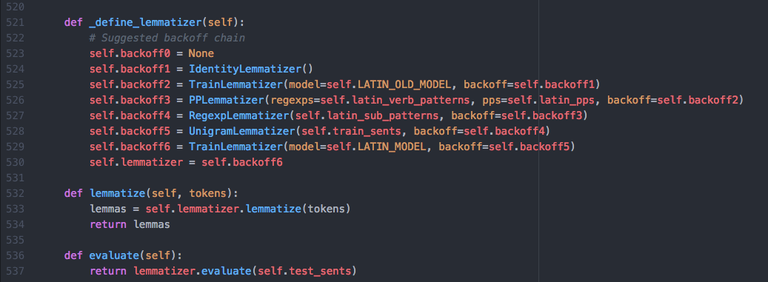
Two major strands of my research agenda at ISAW came together in this paper. First, the digital strand. I have been the Latin Core Tools developer for the Classical Language Toolkit (CLTK) since starting at ISAW. In fact, the paper I delivered at DH2018 was based on updated results from the Google Summer of Code project I participated in during my first summer at ISAW. In brief, this project takes a text annotation technique commonly used for determining the part-of-speech of words in a document called “backoff tagging” and repurposes it for lemmatization, that is, the automatic retrieval of dictionary headwords. In this most recent paper, I discuss the ways in which this method draws on the comparative philological tradition and in so doing offers an innovative alternative to other directions in lemmatization research, most especially the use of machine learning. Through building a lemmatizer that emulates the iterative process of a trained reader of a language—reading, decoding, and disambiguating words, the core of the philological process—I offer CLTK users more flexibility depending on their research question, more transparency in application (that is, it avoids or at least minimizes the “black box” problem), and also a clearer path forward for the most difficult cases.
Second, the comparative strand. I started work on the CLTK in order to better support my interpretative scholarship on Latin literature. Accordingly, the majority of my contributions to the project have been on Latin tools and models. That said, my time at ISAW has given me a much deeper appreciation for the linguistic depth of the ancient world. It is because of ISAW’s language-rich institutional culture that I began to work on the “Getting Started with…” blog posts on learning languages such as Middle Egyptian and Sumerian. Similarly, this environment inspired Future Philologies: Digital Direction in Ancient World Text, a conference that I organized here at ISAW this spring, which brought together scholars working on a diverse range of languages, including Latin, but also Greek, Coptic, Persian, Arabic, Classical Chinese, and Sumerian, among others. All of this has led me to invest more of my development time and energies at the CLTK on a wider swath of historical languages and to shape the platform into a framework for the next generation of computational approaches to ancient world literature.
DH2018 was the perfect venue for promoting digital comparative philology. Because of its international scope, linguistic diversity is usually pronounced at this conference and this year especially so, as the much of the program was bilingual. The opening keynote was delivered in Spanish. Twenty percent of the papers were delivered in a language other than English. All presenters were encouraged to make their slides as accessible as possible to scholars from our host city by translating titles and key points. (My paper also carried the title “Lematización ‘Backoff’ como un método filológico.”) This was all in service of the conference theme “Bridges/Puentes” and I would like to think that my paper on building tools across a wide variety of historical languages fit the theme well.
While the paper was the primary reason for attending the conference, there was much on offer at the event and much worth reporting back to the ISAW community about.
As a researcher in the ISAW Library, not to mention a researcher with a digital projects focus, I have become increasingly interested in the role of libraries in digital humanities work. The Libraries and DH Special Interest Group meeting hosted several dozen librarians and digital humanists. The meeting convened with introductions of all the attendees. As the introductions proceeded through the room, there was an interesting trend in the job titles—Digital Humanities Librarian, Digital Media Librarian, Center for Digital Humanities director, and so on. What is clear is that at universities and related institutions throughout the country, or better yet, the world, “digital” is becoming central to the definition of the “library,” just as libraries are becoming the centers of digital research on campus, often quite literally, as the institutional homes to digital humanities “centers,” “hubs,” “labs,” and so on. In this respect, ISAW is well situated among its peers, with a library that supports digital research, helps our scholars develop digital projects, and helps train our students to be productive scholars in this area. For these reasons, it was nice to have the opportunity to represent our scholarly community and our deep investment in digital work at the meeting.
Unsurprisingly, considering my research interests, I attended several text analysis and natural language processing sessions. I heard interesting papers on verse alignment in medieval poetry, literary character networks, and Classical Chinese character segmentation, but one paper that immediately stands out not only because of its compelling results but also because of the scale of analysis is D.W. McClure and Scott Enderle’s Distributions of Function Words Across Narrative Time in 50,000 Novels. In this paper, McClure and Enderle measured word use at the beginning, middle, and end of a large number of novels and concluded that the results “confirm basic intuitions about genre conventions and the pragmatic requirements of storytelling.” (Be sure to check out the abstract in link above, since it contain some fascinating visualizations of their results.) To pick one case, births tend to appear at the beginning of a novel and deaths at the end. While measuring “basic intuitions” is somewhat interesting, more of surprise in their research is that function words also appear to have a narratological preference. For example, “a(n)” and “the” skew toward the beginning of a novel, yet “a(n)” drops off sharply in the second half while “the” rises. A lot of questions remain, but this work strongly suggests that researchers working with literary text-as-data need to take caution with treating texts (especially longer texts) as homogeneous “bags of words” and be more sensitive to word position. I left this talk with a strong interest in trying its methods on the corpus of Greek and Roman epic poetry. Stay tuned for the results.
Of course, I would be remiss not to mention the other papers with which my paper shared the “Text Analysis, Classical Studies, Manuscripts” panel. Samuel Grieggs discussed advances in the digitization of medieval manuscripts that he is working on with Walter Scheirer’s team at Notre Dame. Annalina Caputo presented exploratory research on the use of “temporal random indexing” to measure the semantic shift of proper names over time. Following my paper, which was third on the panel, Andrew Glass presented on READ, a working environment for born-digital text editions, a project that looks promising for bridging manuscript and epigraphic studies with text analysis and a project sympathetic with my own work in digital comparative philology. Finally, Hong-Ting Su finished the panel with a paper that applied sentiment analysis to Chinese historical texts in an attempt to understand the connection between politics and the reporting of natural disasters. At first glance, the papers on this panel appeared to have little in common, covering as they did a wide variety of topics and a wide range of digital methods applied to the classical and medieval world. But on further reflection, this is exactly the kind of diversity in ancient world studies I have come to expect as a researcher at ISAW and in the end I found myself willing and ready to make cross-cultural and interdisciplinary connections between the papers, connections that I expect will enrich my own work.
My paper at DH2018 is the latest product of ISAW Library’s growing emphasis on research. It follows up on our first conference presentation last year—a poster on geolocating books in the Library’s collection—at DH2017 in Montreal, as well as several presentations in the last year at ISAW and NYU Libraries, not to mention our first hosted conference, this April’s Future Philologies. It was more exciting than ever to attend DH2018, knowing not just how much I could learn from the digital humanities world, but, because of ISAW Library’s emerging research agenda, how much I could contribute to it as well.