Moving forward with Linked Open Data at Pompeii
From January 2020 to June 2023, I was the NYU Principal Investigator on a collaborative project with my colleague Prof. Eric Poehler of the University of Massachusetts Amherst to digitize the contents of artworks - primarily wall paintings - at Pompeii. The work went by the name Pompeii Artistic Landscape Project (PALP) and our efforts were funded by the Digital Art History initiative of the Getty Foundation, to whom we are grateful for their support. PALP made use of the existing digital resources of the NEH-funded Pompeii Bibliography and Mapping Project (PBMP), also directed by Poehler, along with the many thousands of pictures published by Bob and Jackie Dunne at their site Pompeii in Pictures, which is a familiar resources for teachers, students and anyone interested in the archaeological remains at the site. Pompeii, of course, is the city in Campania in Italy that was destroyed by the eruption of Mt. Vesuvius in 79 CE and which is famous for having preserved a vast array of early imperial Roman material culture, including an unmatched assemblage of wall paintings that extensively document both mythic narratives as well as aspects of daily life. This corpus of art is much studied and has been well published, including in the two multi-volume print publications Pitture e Pavimente di Pompei (PPP) and Pompei: Pitture e Mosaici (PPM). The abundance of pre-existing print and digital resources meant that PALP was not starting from scratch when we began work to enable site-wide searching of the content of wall paintings. Our larger goal is that such site-wide search expand the audience that is using this material by easing the process of exploring the rich visual heritage that survives. We hope that newly enabled forms of access will lead to ongoing development of new approaches to the art of the Roman world. Now that the funded period of PALP is over, we are moving ahead with a more generalized effort called simply Pompeii Linked Open Data or P-LOD. What follows here is both a technically-oriented overview of the work completed for PALP as well as an indication of how P-LOD will develop as a foundation for future efforts.
Linked Open Data (and One of its Underlying Data Structures)
Within the world of Digital Humanities, Linked Open Data, or LOD, has proven to be a useful approach to sharing data on the internet, to implementing specific tools for exploring that data (with these tools often appearing as websites), and for enabling links between projects on the basis of shared identifiers and stable URLs. Our work on PALP and P-LOD is inspired by the principles of LOD, both by way of creating a public facing website and, just as importantly, sharing our data in such a way that it can be used by anyone else who might want to search it - or otherwise engage with it - to meet their own needs. These efforts follow from the observation that while public websites are an important part of any project, they can confine users as much as empower them. Almost any website - ours included - will eventually cause its users to want to do some search or try some other interaction that isn't directly supported by the current interface. This hardly counts as a criticism. Not all possible functionality can be implemented at once and it's good that users bring their own ideas to the material. An additional aspect of this circumstance for PALP and P-LOD is that we are outside the context of a current grant that is funding specific deliverables. This means we can explore ideas in an open-ended fashion. So, to some extent, we are also “users” thinking about new ways of interacting with the digital resources that we've collected and created. Accordingly, this article will link to cloud-based environments that are allowing us to model functionality that may make it into a new website funded by a new grant (should we be fortunate enough to get one). All these tools are relatively easy to adapt and readers are encouraged to do so.
Describing our work most generally, PALP and P-LOD are engaged in defining unique identifiers for physical entities and concepts at Pompeii and in relating those resources to each other while also linking them to other digital resources on the public internet. This generic statement can be made practical by focussing on the core data entry that the Getty Foundation grant enabled: the recording of the contents of wall-painting around the site. Pompeii benefits from a pre-existing system of “addresses”. Most Pompeian houses or other properties are identified by a number given to their main entrance. The site has also been divided into nine regions, which are modern; those regions have been further divided into insulae, which are loosely similar to modern city blocks; and then finally each street-facing doorway in an insula is assigned an address such as “Region I, Insula 4, number 10”. Accordingly, the House of Menander - one of Pompeii's most well-known - can be referred to as r1.i10.4, with “4” being the number given to the doorway that is the main entrance to the property. For its part, P-LOD regularizes this address to r1-i10-p4 and that pattern can be applied with a reasonable degree of consistency across the site.
Pompeian addresses are well established and are used in academic articles and also on the Wikipedia pages of well-known houses such as the House of Menander (see the “address” section of the infobox on that wiki page). It is also very useful that the reference work Pitture e Pavimente di Pompei, mentioned above, extends the concept of unique identifiers at Pompeii to the level of the room. Again using the House of Menander as an example, it has over 54 rooms on its ground floor and P-LOD has followed PPP by assigning identifiers such as r1-i10-p4-space-4. This particular room is remarkable for having a cycle of wall paintings with scenes from the Trojan War. It is therefore useful that each wall in this room has itself been assigned a unique identifier by the Pompeii Bibliography and Mapping Project (PBMP). PALP, by way of extending this previous work, undertook to identify individual components of these paintings and all other wall paintings at the site. The east wall of r1-i10-p4-space-4 depicts the arrival of the Trojan Horse and the crowd that welcomed it as well as Cassandra - a daughter of the Trojan King Priam - who warned against accepting the Greek “gift.” Identifying individual components of wall painting allows a simple data structure to be used to connect that painting to its wider context up to the level of Pompeii itself. Somewhat simplifying the process, PALP records the direct statement that a section of the painting on the east wall of Room 4 (we use “space” as a generic term, hence r1-i10-p4-space-4) depicts a horse. The wall is said to be part of r1-i10-p4-space-4, which is said to be part of r1-i10-p4, which is the generic ID for the House of Menander. r1-i10-p4 is part of Insula 1.10 (r1-i10), which is part of r1 (aka “Region I”), which is part of Pompeii. Each of these individual statements is called a “triple”. A triple is merely a statement that has three parts: what is being described (the subject), what is being said about it (the predicate), and the value of that category of information (known as the object of a triple). “r1-i10-p4 is within r1-i10” is a triple saying that the house is in Insula I.10. The details of creating the triples used by PALP are defined by the World Wide Web Consortium (W3C), which is the internationally recognized standards body that enables interoperability of machine-readable data across resources on the internet.
The results of implementing this approach can be seen on the PALP website. https://palp.art/browse/pompeii lists the concepts - which is our generic term for individual elements depicted on Pompeian wall painting - that have been identified to date. Animals are common: following the link https://palp.art/browse/snake shows a map of the many snakes recorded to date along with an image gallery showing the depictions themselves. Gods and mythic figures are also common: see https://palp.art/browse/dionysus and https://palp.art/browse/ariadne. Cassandra - mentioned above - currently is recorded as appearing five times in four rooms: see https://palp.art/browse/cassandra. For each of these links, the triples that connect an individual component of a painting - whether it's a snake or a god - to a wall and then further to a house, insula, and region are compiled into more user friendly representations consisting of a map and images gallery. It would be overwhelming - even unhelpful - to display all the triples that allow the concept “dionysos”, for example, to be assembled and presented at this site-wide level. However, if a user does want to explore the triples themselves, one starting point can be the URL https://p-lod.org/urn/urn:p-lod:id:dionysus. Clicking on that link does not display any map or image gallery. It is mostly a list of the identifiers of individual artwork components that do depict that Olympian deity. A user could click on one of those identifiers and follow the links there to eventually find what house a particular depiction of Dionysus is in. And in doing so, one might become more familiar with the details of how P-LOD represents these relationships. To put that another way, one can become very familiar with our triples by exploring the P-LOD site. But you do not have to engage at this level of detail: if you just want a map of where Dionysus is depicted, stay with https://palp.art/browse/dionysus.
Access to P-LOD Data
An implication of the prior paragraphs is that P-LOD as a project can be described most basically as a collection of triples - that is, three-part statements - about the site of Pompeii. As of this writing, we have collected and published over 2.6 million such statements. And we are grateful for the work of the UMass Amherst students who undertook much of the data entry, some of it during the depths of the pandemic. While the results can be accessed through both current websites at https://palp.art and https://p-lod.org, P_LOD's triples are also available for download as a single file. The link to do that is currently https://p-lod.org/downloads/p-lod-latest.ttl.gz. Users may not find that exact version of our data to be especially useful. For one, at over 220 megabytes when uncompressed, it is large. It also represents the nearly current state of P-LOD's data and as such is essentially always undergoing correction and is steadily being augmented by new data entry. It will have mistakes, though those are being fixed as we continue our work. Lastly, it is in a format that is particular to a type of database known as a Triplestore, meaning a database particularly designed to hold and query large sets of triples. The details of how one loads and queries P-LOD's 2.6 million (and growing) triples lie beyond the scope of this short description. But for those who might want to explore this route to using P-LOD's data, a first step might be installing the open source Apache Jena Fuseki Triplestore on their own machines.
As Curated Triples
In this and the next sections, I will emphasize three additional approaches to access and use our data. The first can be thought of as a transitional stage towards very easy use of P-LOD in current software and cloud-based computational environments. Like many Digital Humanities projects, P-LOD makes its data available on the code sharing site GitHub. https://github.com/p-lod shows all the repositories - some of which are code and some data - currently published by the project. https://github.com/p-lod/p-lod-data is a link to a growing set of files that are meant as cleaned-up and curated versions of subsets of all our triples. For example, the file concepts.ttl contains definitions of concepts - which, again, is our generic term for vocabulary items used to describe the visual content of wall paintings - using the turtle format for defining triples. Searching for “snake” in that file shows that it is readable by us as humans and it also shows the regular structure that allows it to be processed and used by machines. It is fundamental that the concept snake is given the unique identifier urn:p-lod:id:snake which can be used to form the web address (URL) https://p-lod.org/urn/urn:p-lod:id:snake seen above. In the concept.ttl file, rdfs:label is used to give many of the concepts human-readable labels using a standard vocabulary promoted by the W3C. There are also links to WikiData. These are globally unique identifiers assigned by Wikipedia and so support linking to and from P-LOD by other projects that also link their resources to WikiData. As with the file of all 2.6 million triples, readers here - and anyone else - are encouraged to download any of these files or the entire set. By doing so, you have access to the data in the exact same format as the project itself does. Indeed, P-LOD usually considers these files the original version and definition of the information they contain. It is, however, the case that these files are also under development so potential users should expect them to improve over time.
As CSV files
While we believe we are adhering to best practice by sharing our triples, not all software can work with triples out-of-the-box. There are, however, many applications as well as many programming languages that can work with so-called CSV files that format data as rows and columns. Accordingly, P-LOD also uses GitHUb to share CSV files via the repository at https://gitthub.com/p-lod/p-lod-csv. Collectively, these are not yet a complete representation of the project's data. For that use either the full download or the growing selection of cleaned-up triples also on GitHub. Nonetheless, CSV files have a role. Indeed, P-LOD not only shares these CSV files but shares examples of how to use them. https://github.com/p-lod/p-lod-cookbook is a very early version of a set of interactive notebooks that use the Python programming language, which is popular at the moment for both scientific and humanities oriented computing.
At the time of this writing, the cookbook links to a notebook titled “Make bar charts of categorized concepts”. The comments there go into more detail about how that works. The basic flow of the program is that two CSV files are loaded across the internet, the information they contain is then merged using one line of Python code, which puts us in position to make bar charts showing the number of times categories of depicted concepts appear. Figure 1 is an example output. It illustrates the basic point that of the Greek gods considered to be among the Olympians, Dionysus is the most commonly depicted according to current data entry. This is in part explained by his general association with revelry and drinking that makes him appropriate visual decoration for the many rooms at Pompeii that can be used for dining and related activities. And Dionysus also appears alongside Ariadne, the Cretan princess whom Theseus abandoned after killing the Minotaur and whom Dionysus rescued and married. Overall, he is a flexible god and that is one explanation of his popularity. Even a simple bar chart such as figure 1 invites such thinking about the contents of Pompeian wall-painting. And the Python code itself invites user intervention. Anyone who does click through and who does execute it can change ‘olympian_deity’ to ‘animal’ or to ‘bird’ to make a new plot. And our expectation is that such charting capability will be added to the PALP website relatively soon. It will be interesting to link from any charting function to this code so that users can better understand how the visualization they are seeing was made. That is a form of transparency that is also a form of good digital scholarship.
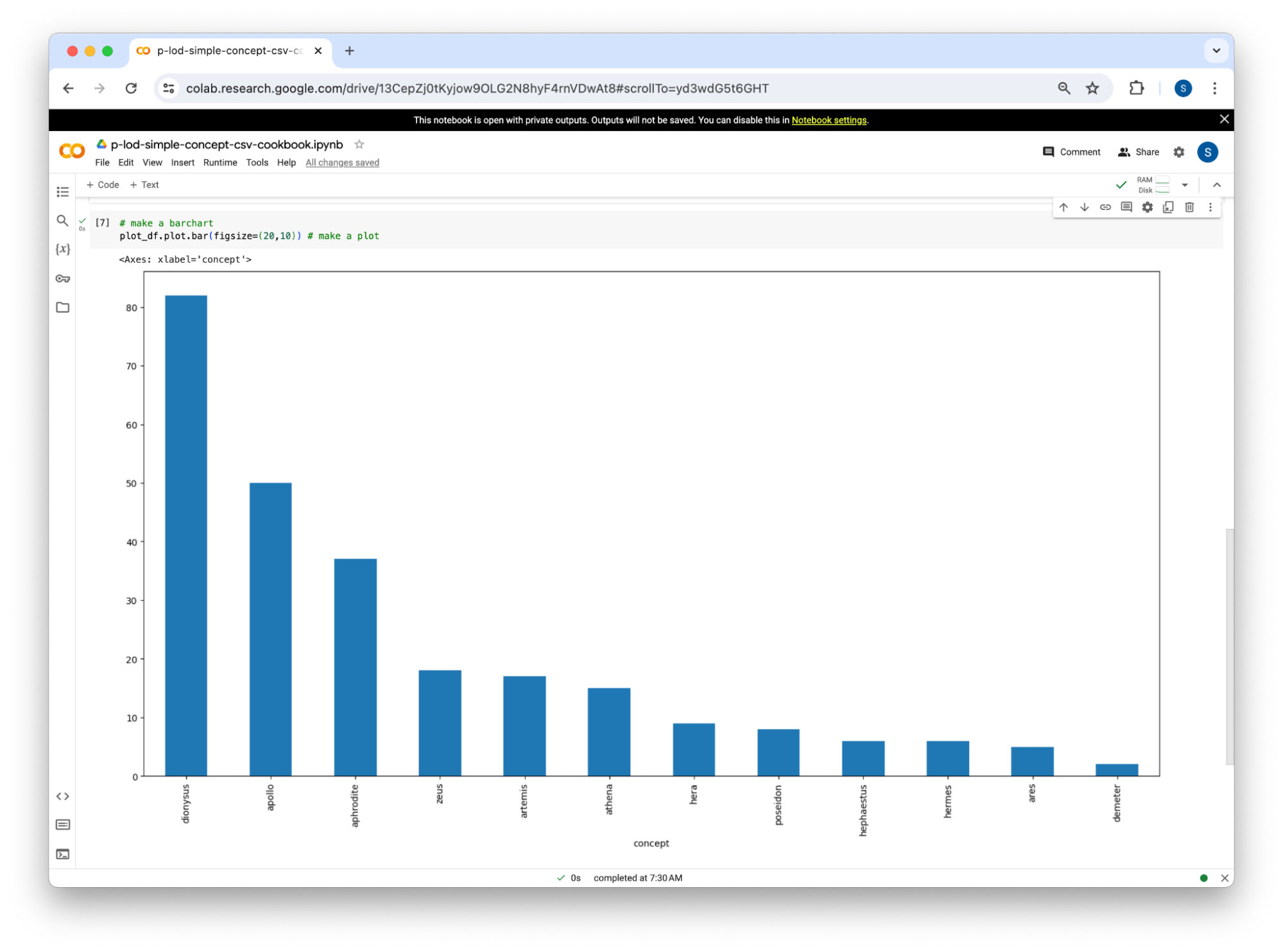
Figure 1: Bar chart made using Python that loads P-LOD CSV files directly from GitHub.
Via the API (and what is an API?)
A third approach to accessing P-LOD data is via its API, or Application Programming Interface. APIs are a pervasive feature of the internet. Even a simple URL works because your browser connects to a server and uses a defined convention to request a named resource, with the name being the part of the URL after the host name. This is a form of API. When browsing the web, the information is returned as an HTML page that your browser displays in readable form. Many APIs return data in a computationally actionable form, which is what the P-LOD API does. An example is the URL https://api.p-lod.org/conceptual-children/olympian_deity. Exactly what a reader sees when they click on that depends on how their browser is configured: some will show the results in a browser window, others will download and save them as a file. Regardless of that detail, that link returns the same list of deities said to be “Olympian” as appeared in fig. 1. And it is also the list displayed on the page https://palp.art/browse/olympian_deity and the same information that appears on https://p-lod.org/urn/urn:p-lod:id:olympian_deity. Repeating these URLs is one indication that P-LOD as a digital ecosystem is able to produce its data in different formats for different uses. Within that context, however, it is important to note that both the palp.art/browse and the p-lod.org/urn URLs call the API behind the scenes and turn the results into more readable versions. Preliminary documentation of how the API can be called is at https://api.p-lod.org/docs.
Another use of the API is to produce a mappable version of P-LOD's data. This capability makes use of the pre-existing standard known as geojson, which is a text-based format for representing and sharing spatial data. A relatively straightforward example of accessing this part of the API is https://api.p-lod.org/geojson/pompeii. The caveats about browser configuration noted above apply here as well. And it is also the case that the result is too long and too filled with latitude and longitude information to be very readable. Fortunately, and because geojson is a widely supported standard, it is easy to render the results of this API call as an actual map. Geojson.io is a website that can do this so that clicking this link (which is too long to conveniently include directly in the text) will display a map of Pompeii, which is a fairly straightforward result. The API also supports creating geojson representations of the distribution of concepts around the site. So https://api.p-lod.org/geojson/snake will return a representation of the distribution of that animal around the site. Again, the raw result won't be very useful so that readers may want to view the output on geojson.io.
The above paragraphs have explored many of the options for accessing P-LOD data. One more mapping related use may continue to demonstrate that our goal is to provide options to users. Digital mapping is a well established practice that is also known generically as GIS (Geographic Information Systems). QGIS is an open source software package that can read geojson data, whether that is available as local files or on the internet via an API such as P-LOD's. This means that QGIS can directly access and use the URLs https://api.p-lod.org/geojson/pompeii and https://api.p-lod.org/geojson/snake. Figure 2 illustrates this capability. It shows a satellite basemap (rendered with a hint of transparency) under the outline of Pompeii over which the distribution of snake is indicated. The image captures the moment that the mouse hovers over the “Add Vector Layer…” item of the “Add Layer” submenu. While this post can't be a QGIS tutorial, choosing that menu item brings up a dialog box into which you can simply paste any P-LOD geojson URL. Click “Add” in that dialog box and the map will be loaded. For figure 2, a little extra work was done to bring in the satellite maps (via “Add XYZ Layer...” on the same submenu), which is also not very hard to set up. The emphasis here is not so much on the result, which can only be a preliminary demonstration, but on the ease of (re)use and the implication that has for allowing anyone to make maps of Pompeii using P-LOD data. This quick overview is really an invitation for readers to explore their own approaches.
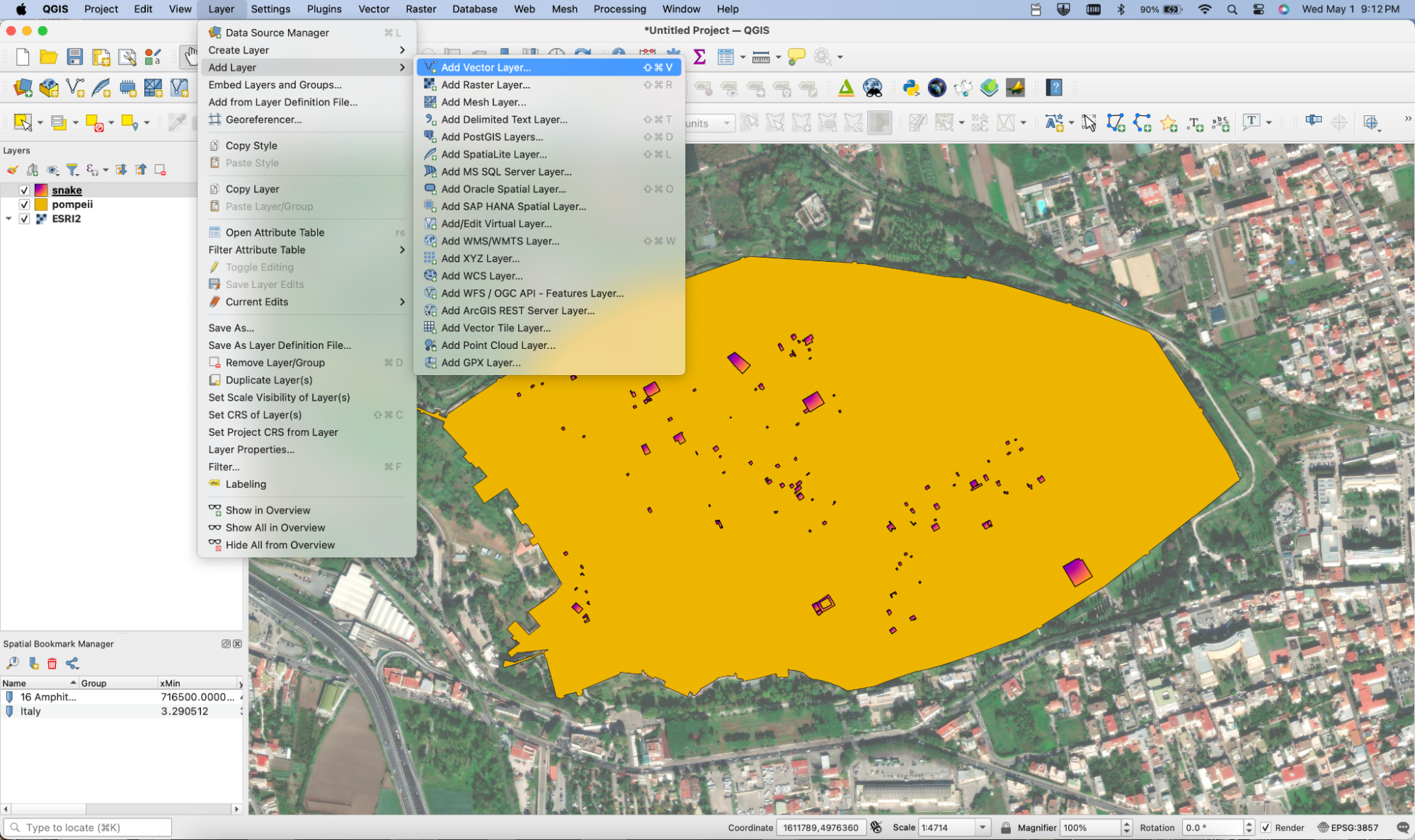
Figure 2: Screenshot of QGIS displaying a map made by calling the P-LOD geojson API.
Finishing the Discussion
How to access our data and examples of what to do with it have been the main themes so far. Download everything, get triples from GitHub, use CSV files by programmatically accessing them across the internet, and using the API to make maps have been the means and methods explored. There is more to say, which will happen in future posts here. An important topic to explore is the use of P-LOD data by other projects. An excellent example at the time of this writing is seen at https://resource.manto.unh.edu/8187817. This is a link into the MANTO project, which is an online dataset filled with details about Greek myth and the characters that populate that world. Following that link will show you an abundance of information about Ariadne, far more than P-LOD is likely to collect itself. And given that P-LOD's own link for Ariadne itself links to MANTO's, our users can take advantage of that project's efforts. And vice-versa: MANTO links to us. This is one aspect of cooperative linked open data on the internet. Work by independent projects adds context for each one. P-LOD also links to well-established resources such as Wikidata and the Pleiades project, which is a gazetteer of ancient sites that includes many houses and other features at Pompeii. The hows and whys of such linking are worth further discussion in another post.
The latter parts of the talk on which this discussion is based looked forward to new forms of computation that P-LOD is exploring. That is a reference to Generative AI (gAI) and it is important to note that introducing such tools into the P-LOD ecosystem should not be done just to follow the hype associated with them. gAI raises issues of copyright, environmental impact and usefulness of output that deserve fuller discussion. Within the context of these concerns, it is the case that the ability of Large Language Models to provide context for the many aspects of Ancient Mediterranean culture that are represented on Pompeian wall-paintings has potential to help users of our tools explore the content and connections inherent in those artworks. The P-LOD cookbook mentioned above does include notebooks that begin to implement Machine Learning (ML) and gAI methods. As that work moves ahead, it will also be discussed in a future post here. Stay tuned.