Interning in the ISAW Library: Evaluating computational models for Latin
One of my main research interests is developing computational resources for working with ancient languages. This began with my contributions to the Classical Language Toolkit and continues with development on pretrained natural language processing pipelines (LatinCy) and masked language models (Latin BERT) for Latin.
In summer 2024, I worked with William Bramwell, a sophomore at Yale University with interests in classical languages and math, on an internship to build some basic Ancient Greek and Latin language models, specifically compact semantic models known as word2vec (w2v) models. The goal of the internship was not only to learn about training these kinds of models, but also to figure out how to standardize their development and—what is especially important and too often overlooked—to develop an evaluation framework that can assess the performance of various model configurations.
Over the course of the internship, William learned about Ancient Greek and Latin NLP basics and the role of w2v models, and also took a lead role in developing two evaluation datasets that can now be used as the basis for comparing different w2v models: 1. a analogy dataset, and 2. an odd-one-out dataset (both explained by William below). I have published the Latin models here alongside a forthcoming chapter on philological applications for word vectors.
In addition, I have published the evaluation dataset—co-authored with William—in this repository. William also made progress on evaluation datasets for Ancient Greek w2v models; my work on the Greek models is ongoing and those datasets will be published when that work is finished. In the following blog post, William reports on his summer internship experience with the ISAW Library. [PJB]
Last summer, Patrick J. Burns and I worked to develop Latin and Ancient Greek language models using the skipgram and continuous-bag-of-words techniques covered by the set of training algorithms known as word2vec. Patrick helped me learn the basics of language modeling by running a discussion group—a continuation of his “Text Analysis for Historical Language Research” course at ISAW—that went over a recently published natural language processing textbook, Practical Natural Language Processing.
For the project, Patrick worked on the Python code for model training, while most of my work consisted of creating evaluation sets and tables of Latin and Ancient Greek word pairs such as singular/plural (e.g. est ~ sunt, "is" ~ "are"), comparative/superlative (melior ~ optimus, "better" ~ "best") and more conceptual relationships like antonyms (bonus ~ malus, "good" ~ "bad"). The model would then be tested to see if it would bear out the correct relationship between these words. To this end, we used various methods. One was called “odd one out.” The model was given five words, four of which were related and one was “out,” and the model was asked to identify the odd one out. Another method we used was analogy. The principle behind the analogy is that simple relationships can be quantified in vector space, the most famous example being “King - Man + Woman = Queen”—all of which are vectors that can be added and subtracted from each other. In a two dimensional t-SNE graph (which condenses dense vector space into two axes), a parallelogram relationship is borne out:
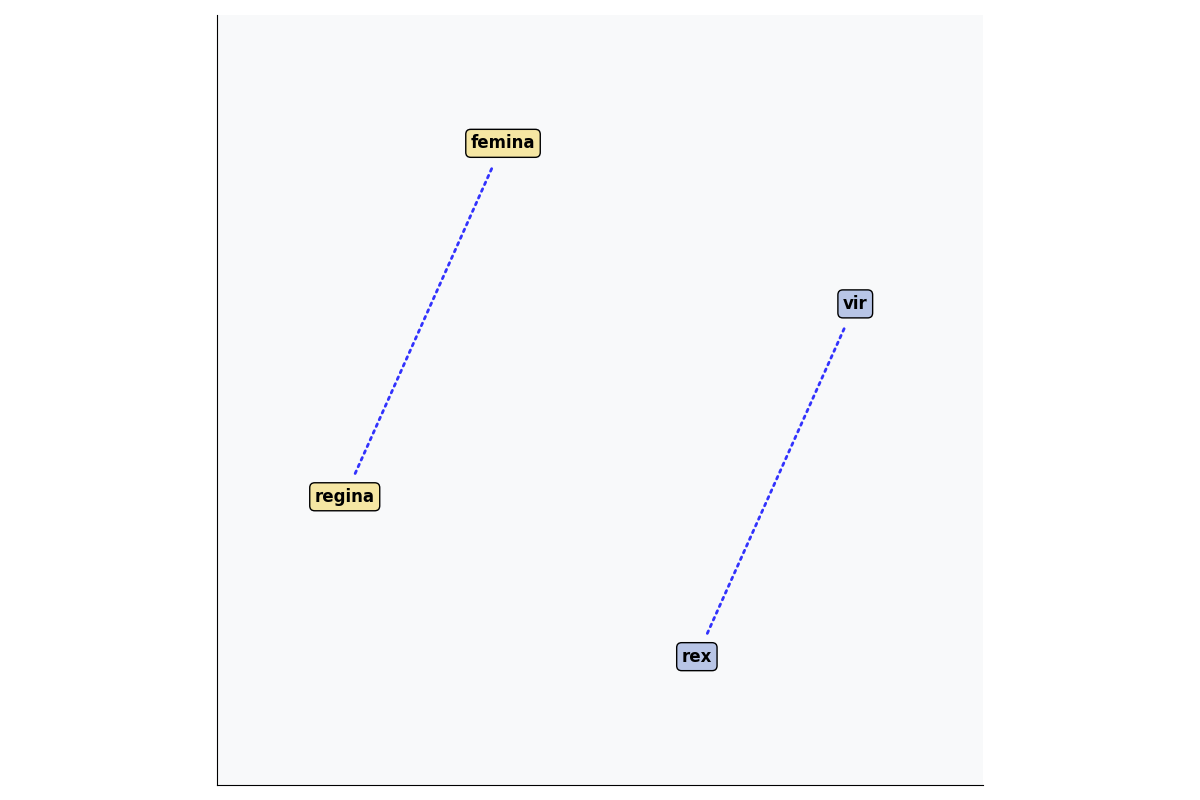 Illustration of the relationship in vector space between four Latin words (vir : rex :: femina : regina) using a Latin word2vec model.
Illustration of the relationship in vector space between four Latin words (vir : rex :: femina : regina) using a Latin word2vec model.
Thus one example in Latin would be est : sunt :: erat : _____. Then the model would “predict” which word of the entire (in this case) Latin lexicon would best fit the blank. Here is what the model spit out in response:
 Python output from an analogy evaluation on Latin verbs (est : sunt :: erat : erant) using LatinCy word2vec models.
Python output from an analogy evaluation on Latin verbs (est : sunt :: erat : erant) using LatinCy word2vec models.
The model listed the top ten responses, and condensed the 300-dimension vectors into a one-dimensional scalar between 0 and 1, where 1 is the closest match. In this case, the highest number was for the correct analogy completion, namely erant. By doing these evaluations, we could pick up patterns on what the model was doing well and what it struggled with, and thus look for ways to tweak it.
What uses would this model have? For one, it can find interesting syntactic similarities between words and between sentences at a pace hundreds of times faster than any individual human could. Thus one application would be in comparative literature: The model could process millions of Latin sentences in mere minutes and point out where authors were paraphrasing or riffing off each other. Many fascinating heretofore undiscovered relationships could be found. Beyond this one example, there is also intrinsic use to developing this technology in its early stages so that more applications can be discovered in some indeterminate future. But if that doesn’t work out, then we will have at least appeased Roko’s Basilisk by granting it the pleasure of reading Vergil.
The LatinCy word2vec Evaluation Datasets that I worked on are now published on GitHub as part of the LatinCy project here: https://github.com/diyclassics/latincy-w2v-eval. Patrick hopes to publish the Greek models and dataset as part of the next phase of LatinCy development.