Experimenting with the ISAW AI Librarian
The following is a guest blog post by Federico Di Pasqua, who spent several weeks in the ISAW this term experimenting with deploying generative AI to find potential avenues for making ISAW Library collections and data more discoverable and useful.
While Large Language Models, such as ChatGPT or Gemini, are becoming ever more integral to our daily lives, this technology is largely failing to deliver on its promises when it comes to addressing domain-specific knowledge. In simpler terms, when asked to draft an email to HR or a note for my niece’s birthday, the effectiveness of, say, ChatGPT is apparent. For most academic communities, however, it is not possible yet to rely on these technologies to address scholarly queries in a productive fashion; and in the case of ISAW, none of the current models can make reliable connections with respect to ancient world knowledge.
As a guest scholar of computational humanities at ISAW, I tried to leverage my training in software engineering and Classics to confront this challenge. Drawing on the experience and expertise of Sebastian Heath, Riccardo Torlone, and Patrick J. Burns, I developed what I am calling the ISAW AI Librarian, a prototype of an application that allows scholars of the ancient world to ask questions about, and draw connections from, open access ISAW collections (the code is available here). For this multilingual tool, I focused my work on the texts of the born-digital journal ISAW papers, the Digital Central Asian Archaeology (DCAA) Collection (primarily in Russian), and the Ancient World Digital Library (AWDL), together totalling almost two thousand volumes and scholarly articles. (ISAW Papers are distributed under a Creative Commons-Attribution license; texts in the DCAA and AWDL have either been cleared by the rights holders, as specified in the rights statement attached to each work, or are in the public domain.) The AI Librarian leverages Augmented Retrieval and Large Language Models to access information and draw semantic connections based on these specific ISAW archives. Each of its answers or observations is paired with a bibliographic reference to ensure the veracity of the information provided.
Although my work at ISAW focused on three specific repositories, mostly concerned with the Mediterranean and Central Asia, the pipeline I developed can be applied to any research material. Importantly, this is an exploratory research project aimed at investigating the avenues of inquiry opened up by generative AI technologies, rather than a finished or polished product. It is a step toward understanding how these tools can complement scholarly workflows and enhance research practices in the humanities.
In the following, I am breaking down the steps to be taken by any ancient scholar who wishes to build their own AI Librarian.
Data collection and preprocessing
The first step involves loading the texts in the various collections and dividing them into small chunks that the application can process. The pipeline provides each text portion with metadata, such as source and page number, to ensure the AI Librarian’s retrieval of this information. The three collections were available in different formats: (1) online documents in easily parseable HTML; (2) PDFs already processed through Optical Character Recognition (OCR); and (3) non-OCR PDFs. Each format required distinct techniques for text loading and segmentation. This variety of formats enabled me to develop a versatile pipeline applicable to a wide array of scholarly projects.
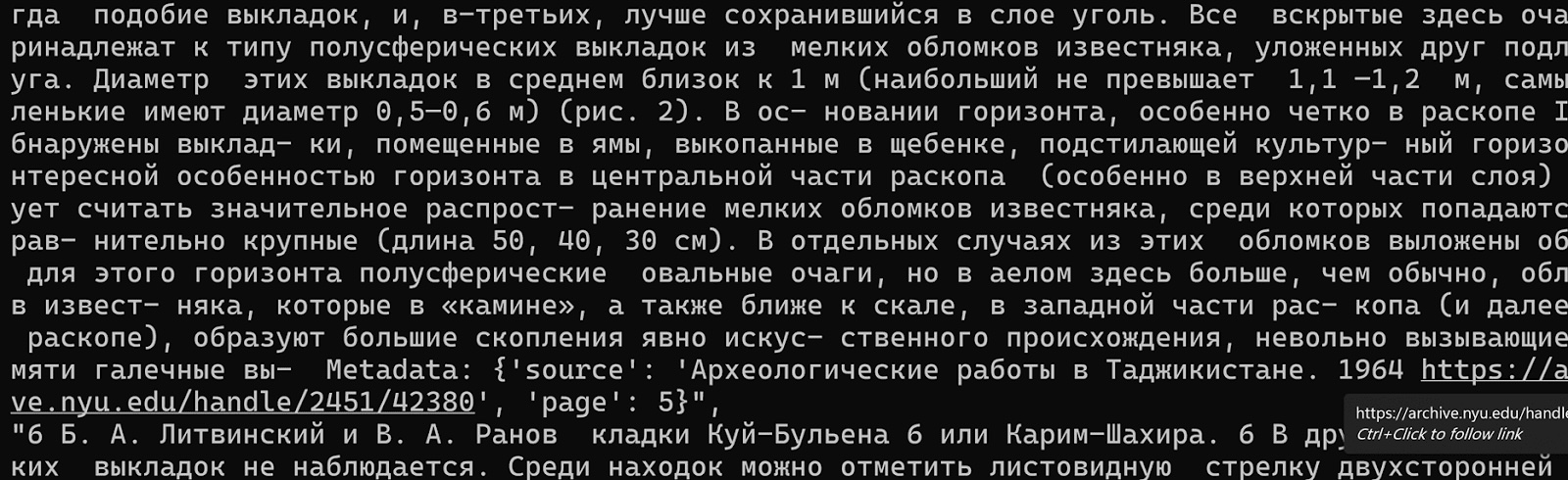 A chunk of text from the Digital Central Asia Archaeology collection, including a reference to its title, URL, and page number.
A chunk of text from the Digital Central Asia Archaeology collection, including a reference to its title, URL, and page number.
From data to vector
At this stage, each text chunk is collected in a vector store. The ability to turn text into a vector is what enables the machine to draw semantic connections between one bit of text and another. A vector space is a mathematical framework where concepts are represented as points, and their closeness or distance reflects how related they are semantically. Namely, if I’m asking a question about "vases" at Kenchreai, the AI Librarian will retrieve the chunks regarding "pottery" or "amphorae" located in that site, because these vectors lie in the same region of the vector space. This also allows the ISAW AI Librarian to make recommendations between researcher interests and semantically related content (see below).
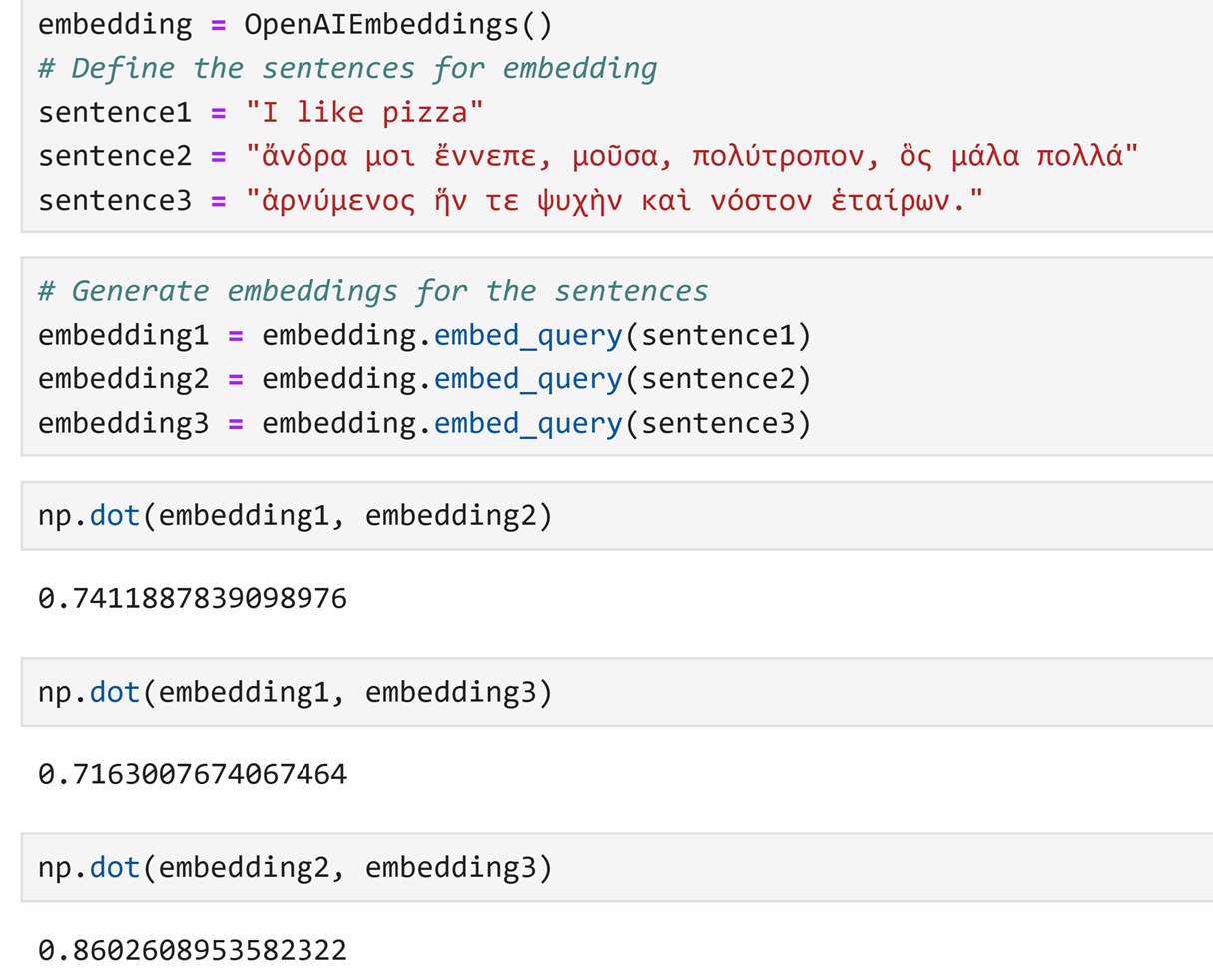 A python notebook showing the semantic connections between sentences. Sentence1 (I like pizza.) shows a semantic similarity of 74% with sentence2 and 71% with sentence3. Sentence2 and sentence3, which are two verses from the Odyssey, demonstrate an 86% semantic similarity with each other.
A python notebook showing the semantic connections between sentences. Sentence1 (I like pizza.) shows a semantic similarity of 74% with sentence2 and 71% with sentence3. Sentence2 and sentence3, which are two verses from the Odyssey, demonstrate an 86% semantic similarity with each other.
User interface
The AI Librarian user interface consists of two main components. The first is a simple search bar where a question or a prompt can be inserted. The second and larger text box allows scholars to input their research interests or an article abstract, in order to prompt the AI Librarian to draw connections between the input text and the content of the imported ISAW archives. Several prompt engineering features allow the user to facet or refine their queries and select a given output language. The example shown about horses in Eurasia includes options to refine the query by selecting research areas like Art History, Archaeology, and Ancient Medicine, and answers cite examples and page numbers, along with a source link. Independent of the language of the text source, the interface provides answers in English or the chosen language, facilitating access to sources that may not be familiar to all users (many ISAW researchers come from international academies and work in languages in addition to English). I find this feature quite helpful while consulting the material from the Digital Central Asian Archaeology collection.
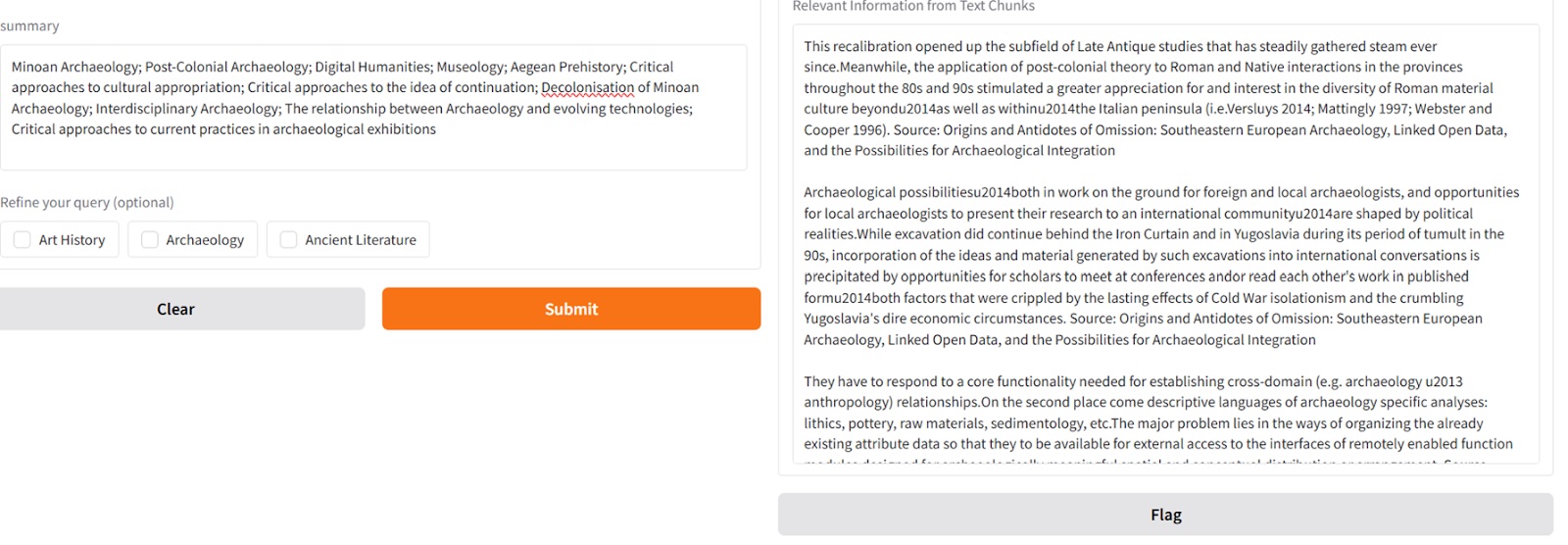 A screenshot of the AI Librarian making recommendations on the basis of the indicated interests of archaeology scholar semantically related to ISAW papers and articles.
A screenshot of the AI Librarian making recommendations on the basis of the indicated interests of archaeology scholar semantically related to ISAW papers and articles.
Conclusion
Research assistants such as the ISAW AI Librarian present new opportunities for scholars of the expanded ancient world to leverage generative AI as an avenue for humanities and research inquiry. These applications, with their ability not only to retrieve information from large textual repositories, but also to summarize, generate question-answer pairs, and extract features from a given prompt, allow the scholarly community to expand their research toolset. Critically, the open access resources that the application drew from do not infringe any author’s or institution’s copyright. I hope this example can prompt researchers to explore the opportunities provided by generative AI and encourage institutions to continue expanding access to open data, so as to advance the ability to retrieve and share knowledge.